The AI Revolution: What, Why Now, and What It Means
Session 01 — GenAI & Research
This opening session establishes why generative AI demands serious attention from researchers, situates it within a longer history of artificial intelligence, and examines its measurable impact across science, law, creative work, and learning. We cover three questions in sequence: what AI actually is (cutting through the hype), why the current wave arrived when it did, and to discuss evidence about its effects on work, knowledge, and society. The goal is start the course with a bird-eye view of the current situation.
Welcome and Introduction

Welcome. It is genuinely difficult to think about anything else these days — generative AI is everywhere, and it deserves serious attention. This semester we explore it together. I have experience, and I have answers to some questions. But things are moving fast enough that you are on the front row of a story still being written, and we will make sense of it together.
My Obsession: Causality and Causal AI

My passion — and my professional obsession — is causal inference. I want to convince you it is one of the most important fields in science, because virtually every question worth asking is a causal question: What caused climate change? What is the impact of this policy? Will this master’s program lead to a fulfilling career?
My research has been applied from the start. I worked on questions such as the effect of arms transfers to Africa on conflict intensity and refugee flows — not from behind a desk, but for example in direct dialogue with leading organisations shaping arms-transfer policy. When COVID hit, I was connected to the Swiss policy task force, working on the causal question no one could avoid: do lockdowns work?
My Goal: Helping Society Make Better Decisions

I realised that causal inference was widely misunderstood — even among decision-makers — so I set out to make it accessible. I give talks to C-suite executives, CFOs, researchers, ML engineers, and decision makers worldwide. The core message is always the same: here is how to think rigorously about cause and effect, and make reliable decisions.
My book distils this into a non-technical but rigorous framework — the kind of structured thinking economists do naturally, asking constantly: Is there an endogeneity problem? An omitted variable? What is threatening this causal claim? Most people have never been taught to do this systematically. The book is an attempt to change that.
Then GenAI Hit the World
I remember the Wednesday in November 2022 when ChatGPT arrived. Not AI in general — AI had been around — but something shifted. Even my first trivial experiments, asking it to write a poem for my brother, made clear that a threshold had been crossed.
Since then, measuring the impact of generative AI has become central to my work. It is, after all, a causal question: what does this technology actually do, to whom, and through what mechanisms? My goal is to provide educated, evidence-based answers — and to be honest about how much remains unknown.
GenAI Impact is Unknown

I have recorded conversations with experts worldwide on the impact of AI — on mathematics, learning, writing, disease detection, legal work, critical thinking, and geopolitics. These discussions inform this course directly. I will reference them throughout the semester, not because they are definitive, but because they show smart people grappling seriously with hard questions. That is the spirit I want for this class.
I’ve Trained 15,000+ People
About eighteen months ago I left my academic position — not out of frustration, but because I concluded it was not the highest-leverage way for me to contribute. Today I work as a solo entrepreneur. I still teach extensively in different academic institutions, but most of my time I provide workshops and keynotes on causal inference and AI impact measurement to large organisations. My focus is practical: helping companies and institutions understand what AI actually does to their work, their decisions, and their future.
The Rise of Big Tech
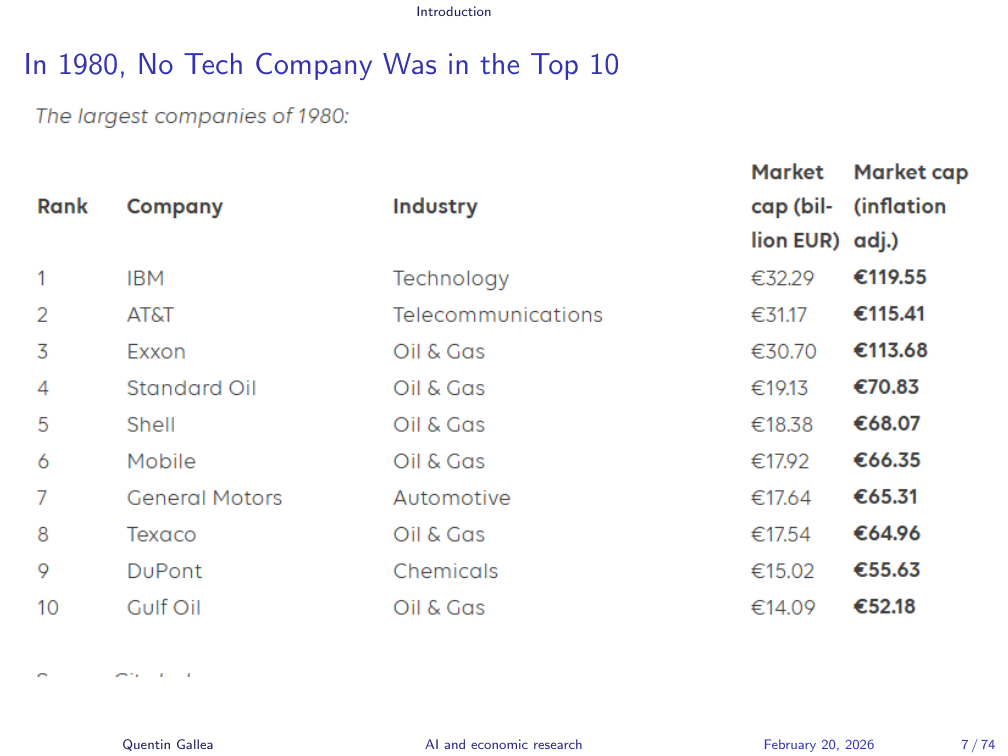
In 1980, the ten largest companies in the world by market capitalisation were in oil, chemicals, automotive, and telecommunications. One technology company appeared: IBM.
Today, 7 of the Top 10 Are Tech Companies
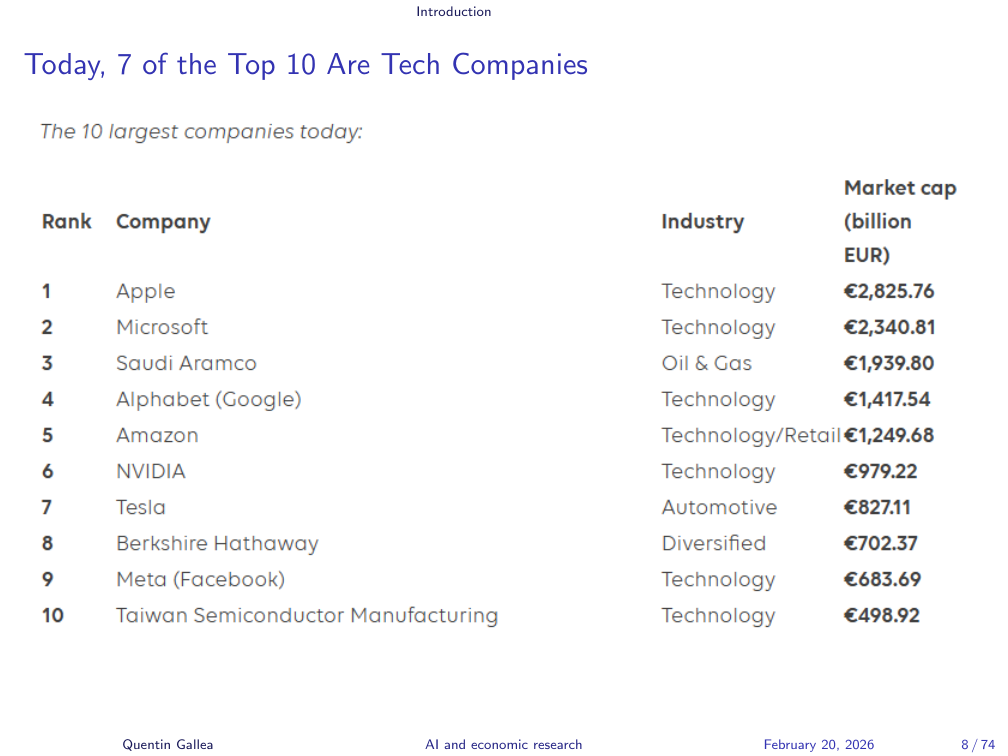
Today, seven of the top ten are technology companies — almost all American — and most have artificial intelligence at their core. Apple, Microsoft, Alphabet, Amazon, Nvidia (providing the chips for all of this computation), Tesla (whose autopilot is an AI system), Meta (whose recommendation algorithms keep us scrolling), and TSMC (the semiconductor manufacturer in Taiwan whose products run everything from your fridge to your laptop).
The world transformed rapidly, and AI is at the centre of that transformation.
NVIDIA’s Market Cap Grew 10x in Two Years
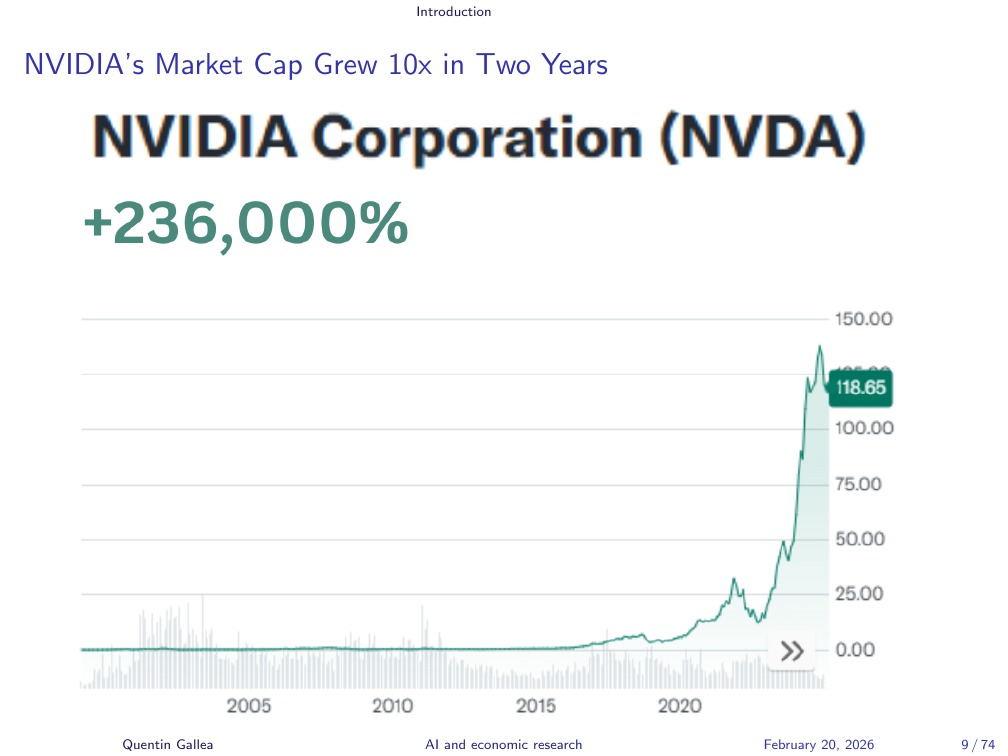
Nvidia is the clearest emblem of this shift. Its GPUs (graphical processing units) were originally designed for gaming. What made them valuable for AI is their ability to parallelise computation — to run many operations simultaneously. Training a large language model requires enormous numbers of matrix multiplications: simple operations, but billions of them. GPUs handle this far more efficiently than standard processors. As AI demand exploded, so did Nvidia.
AI Is Concentrating Power in Very Few Hands

The consequences extend well beyond economics. The image of the world’s most powerful technology executives standing behind Donald Trump during his second inauguration is a signal worth taking seriously. AI is not just reshaping markets — it is reshaping power.
AI Fears
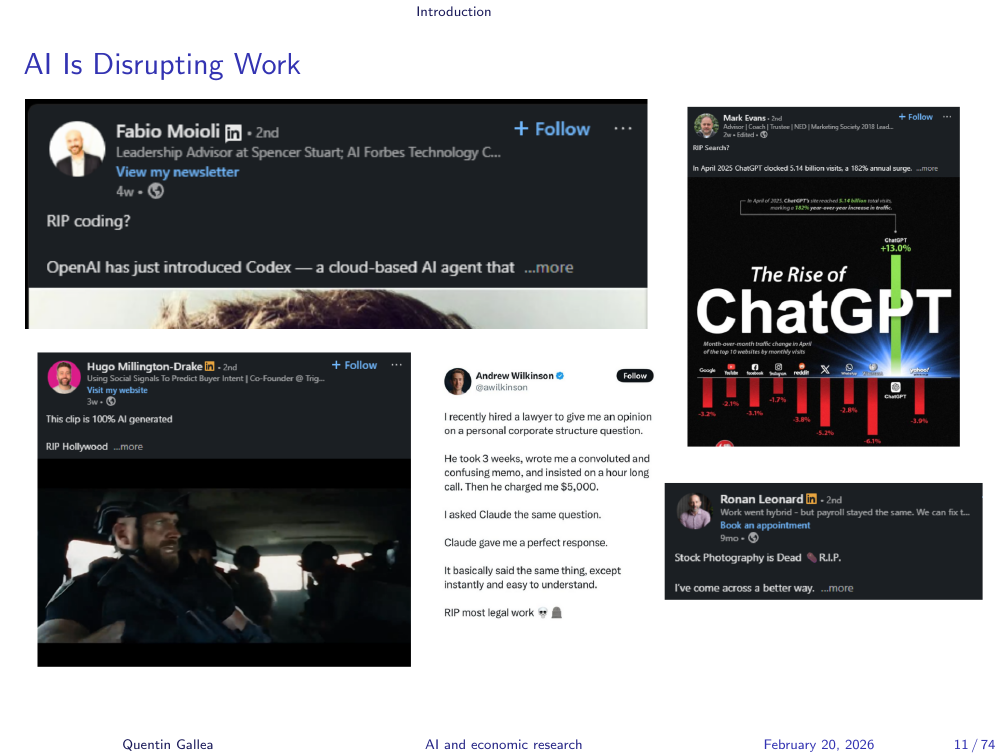
Social media is full of sweeping claims: AI will destroy legal work, search, Hollywood, creative writing. Some of these claims are exaggerated. Some are not. Research — conducted by highly trained people who spend years developing expertise — is clearly in scope. Whether and how it is affected is a central question of this course.
Trace of LLMs in Research
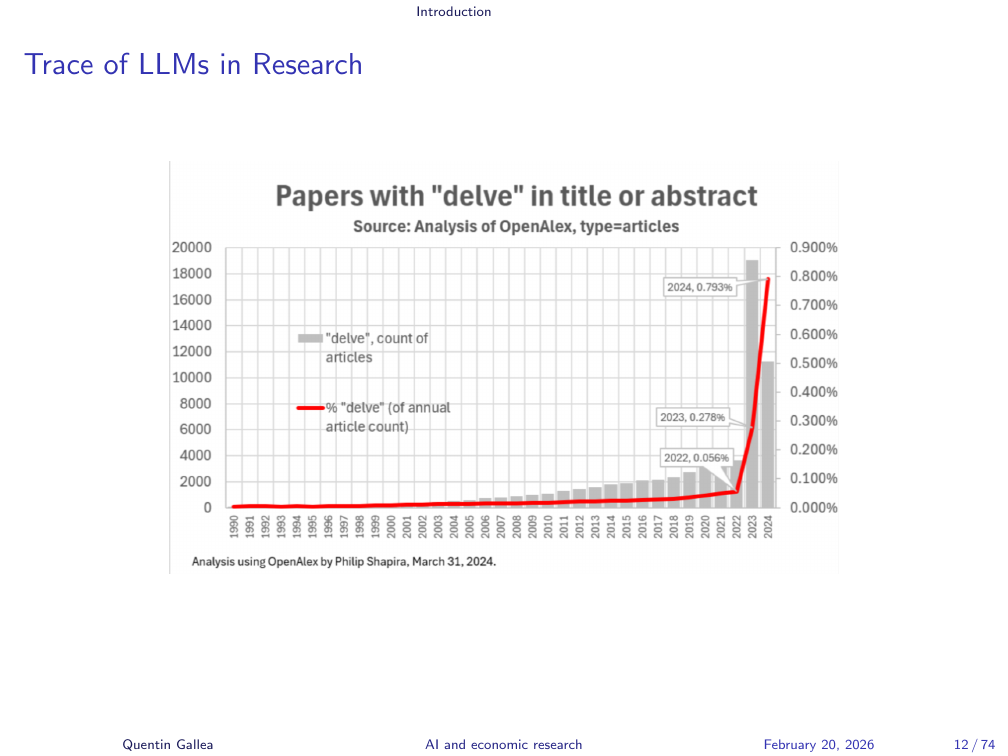
The traces appeared quickly. The word “delve” — virtually absent from academic abstracts before 2023 — exploded in frequency almost overnight after the release of ChatGPT 3.5. The chart tells the story clearly. Researchers are using these tools, at minimum to polish English prose — understandable, given that most researchers write in a second language.
But these tools can do far more than fix grammar. They can generate code, synthesise literature, and assist with analysis. Every stage of the research process is affected, which is precisely why this course exists.
Suddenly Bad Research Tsunami

The first downstream effect was a flood of low-quality papers. Paper mills — operations that mass-produce papers and cite each other to inflate citation metrics — already existed. Generative AI dramatically increased their throughput. The peer review system, already under strain, faces a genuine challenge in filtering signal from noise at scale.
Trying to Automate the Whole Process
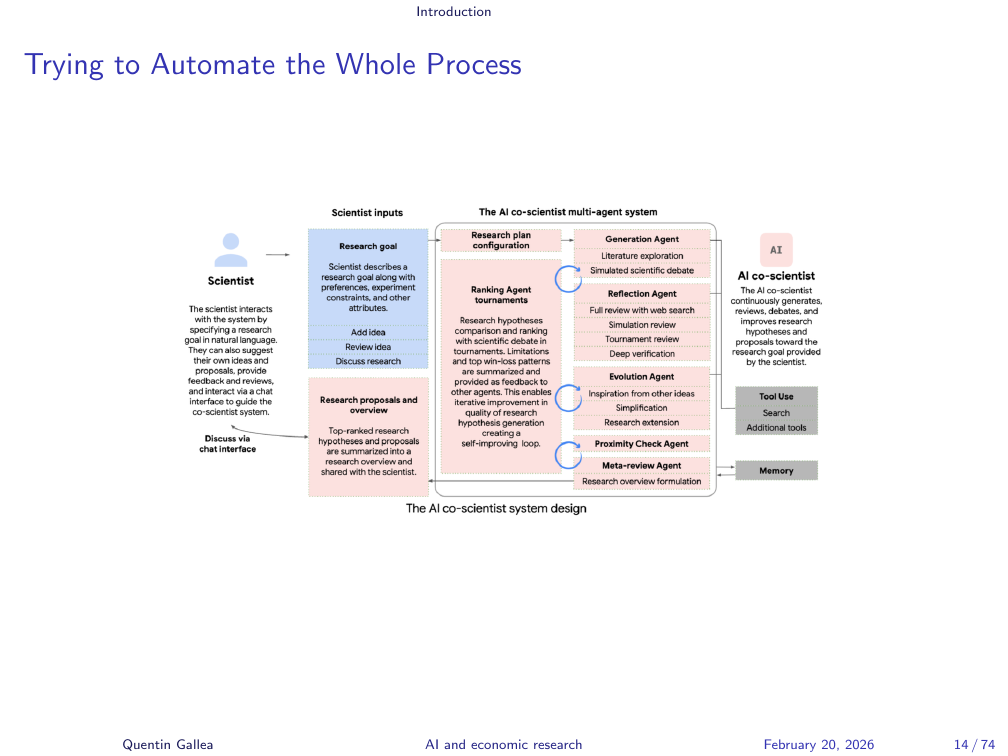
Google and others have invested heavily in automating not just individual research tasks but the entire scientific process — from hypothesis generation through experimentation to publication. Google’s AI co-scientist project is one example. These systems have not yet been released broadly, but the direction is clear and the pace is relentless.
And Today? A Thesis in 10 Minutes

Last week, I ran an experiment. Using a single prompt — one question — I asked Claude Code, an agentic AI system installed locally on my computer (and took 10min to setup for this specific task), to write a research paper. Claude Code can create folders, write and execute code, run econometric analyses, generate figures, and produce documents. I spent ten minutes. The system worked for about an hour. The output: a complete 40-page paper.
You will read that paper before next week’s session and share your assessment in class.
No Wait! 5 Papers per Day!
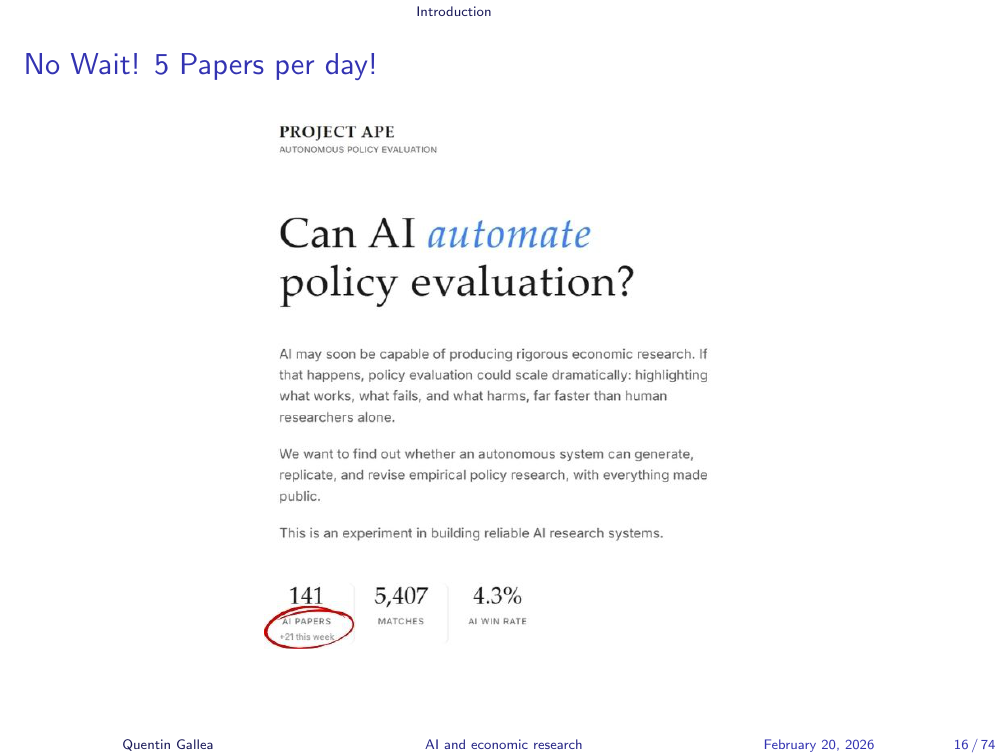
A serious, top-tier researcher named David Yanagizawa Drott (UZH) — has gone further. He has automated the full research pipeline: writing papers, reviewing submissions, acting as a referee, and iterating through revisions, all using generative AI in a system similar to what I am building. His current throughput is five (arguably) high-quality papers per day.
This is where we are — not in some hypothetical future, but right now. We went from ChatGPT 3.5, which was amusing but limited, to a technology that directly challenges what a PhD researcher does. This does not mean researchers will disappear. But the transformation is deep, and most of my academic colleagues have not yet engaged seriously with it. They have never opened Claude Code. Many have still basic knowledge of GenAI.
During this class we will extensively question the pros and cons of such automation, as well as the potential broad and deep impact on the research world.
The pace is the point. We have to experiment, test, and think carefully about where this is going.
Course Overview

If core research tasks can be automated, that is both an opportunity and a threat — especially for those at the start of their careers. The goal of this course is to figure out, together, what the risks are, what the opportunities are, and how to use these tools in ways that genuinely advance knowledge and careers.
[Student: “Won’t human judgment always be discounted by this? I mean, there will always be a question of trust — I’ll always kind of discount the AI.”]
That is an important point, and we will return to it throughout the semester. AI makes mistakes. Humans make mistakes too — and humans have bad incentives. In academic research, “publish or perish” creates pressure to make results look cleaner than they are. I am not arguing AI is better. I am opening the question: at what point, and for what tasks, does the balance of errors and incentives favour AI, favour humans, or favour some combination?
David Yanagizawa Drott’s bottleneck is instructive: he can produce five papers per day, but human peer reviewers cannot keep pace.
We’ll Learn Research the Old Way — Then the AI Way

The structure of this course reflects this tension. We begin, two weeks from now, with traditional research methods — how things have been done. Then, step by step, we examine how generative AI can assist at each stage, and what is lost or gained when it does.
The goal is not just to learn tools. It is to produce a defensible, considered answer to the question: what is the efficient way to do research today? I want this course to function as a lab. The results of our thinking and experiments will go online — which is why I am recording. I can give the slides and the transcript to Claude Code and have it generate a full lecture page — and then of course I will double-check that I did not say anything I should not, or that there are no mistakes in the transcript.
Your Semester at a Glance
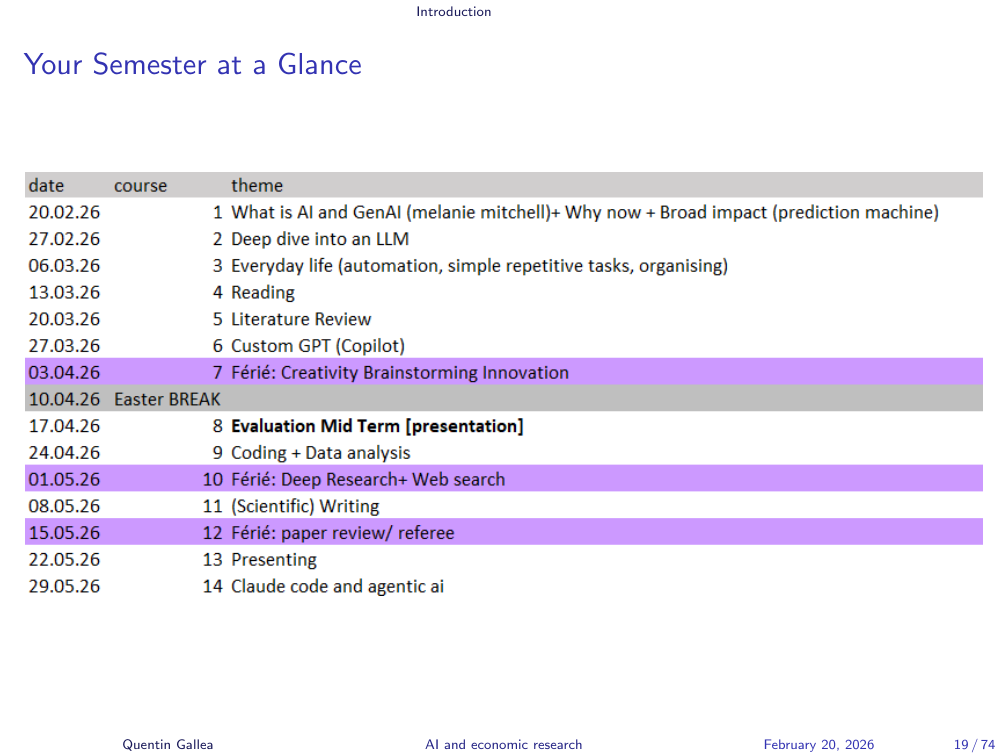
Today covers the foundations: what is AI, why did it emerge now, and what is its impact. Next week we dedicate a full session to how large language models actually work — understanding the architecture helps anticipate and interpret model behaviour. The week after, we cover everyday use of LLMs and prompting, because the class needs a common baseline before we go further.
From there, we follow the research process in sequence: reading papers, conducting literature reviews, generating hypotheses, coding and data analysis, web search and deep research, scientific writing, peer review, presentation, and finally an extended look at Claude Code as an agentic research system.
Course Evaluation: Theory + Practice + Critical Thinking

Given that a 40-page paper can be generated in ten minutes, the evaluation is not going to be about documents. It is about thinking.
The first component (20%) is an in-class group presentation of a Claude Skill you design. The evaluation focuses on the problem you chose to solve, your critical assessment of what the tool can and cannot do, and your ability to connect the design choices to concepts covered in the course. A grading grid will follow shortly.
The remaining 80% is a master’s thesis research proposal developed iteratively over the semester. Each week’s topic — literature review, hypothesis generation, coding — maps directly onto a stage of your proposal. You work on something you genuinely care about, applying that week’s concepts as you go. The semester ends with a 15-minute individual oral exam in which you present your proposal, walk through how you used generative AI at each stage, critically assess those choices, and answer conceptual questions about the course material. An example question: what is temperature in a language model, and when would you want it higher or lower?
“AI Won’t Replace Researchers — But Our Work Is Changing Completely”

[Student: “If AI augments productivity so dramatically, does that mean fewer researchers will be needed? And does this widen the gap between countries with and without access to these tools?”]
Both are real concerns, and both will come up throughout the semester. The impact on the number of researcher is unclear (and unknown), but we will try to find some answers. On the second: the automation (APE project) is partly motivated by a social goal — making rigorous impact evaluation accessible to organisations that could never afford a team of PhD researchers and econometricians. Think of a public health agency in a low-income country trying to evaluate whether a malaria bed-net programme works. That kind of analysis currently requires rare expertise. If it can be automated responsibly, that is a genuine good. But of course, the concentration of AI capability in a handful of wealthy countries and companies is a geopolitical fact we cannot ignore. The same tools that can spread opportunity can also entrench inequality.
What Is AI?

The rest of today addresses three questions: What is AI? Why did it happen now? What is its impact?
What is AI?

Nobody Agrees on What “Intelligence” Means

Wikipedia defines artificial intelligence as “the capability of computational systems to perform tasks typically associated with human intelligence — such as learning, reasoning, problem solving, perception, and decision making.” It is vague, but that vagueness is informative. Intelligence itself is contested.
AI is often called a suitcase word — packed with a jumble of different meanings. Depending on the context, “AI” can refer to a chess engine, a recommendation algorithm, a large language model, or a protein-structure predictor. Keeping these distinct matters for this course.
When AI Succeeds, We Move the Goalposts

John McCarthy observed a consistent pattern: as soon as an AI system achieves a task we considered intelligent, we reclassify the task as “not really intelligence.” Chess was once the canonical test of human intellect. When Deep Blue defeated Kasparov, the response was “it just memorises — that is not real thinking.” This goalpost-shifting makes AI hard to define, but it is a useful observation: we consistently underestimate what machines can do, then rationalise the achievement away after the fact.
Four Ways to Categorize AI Systems
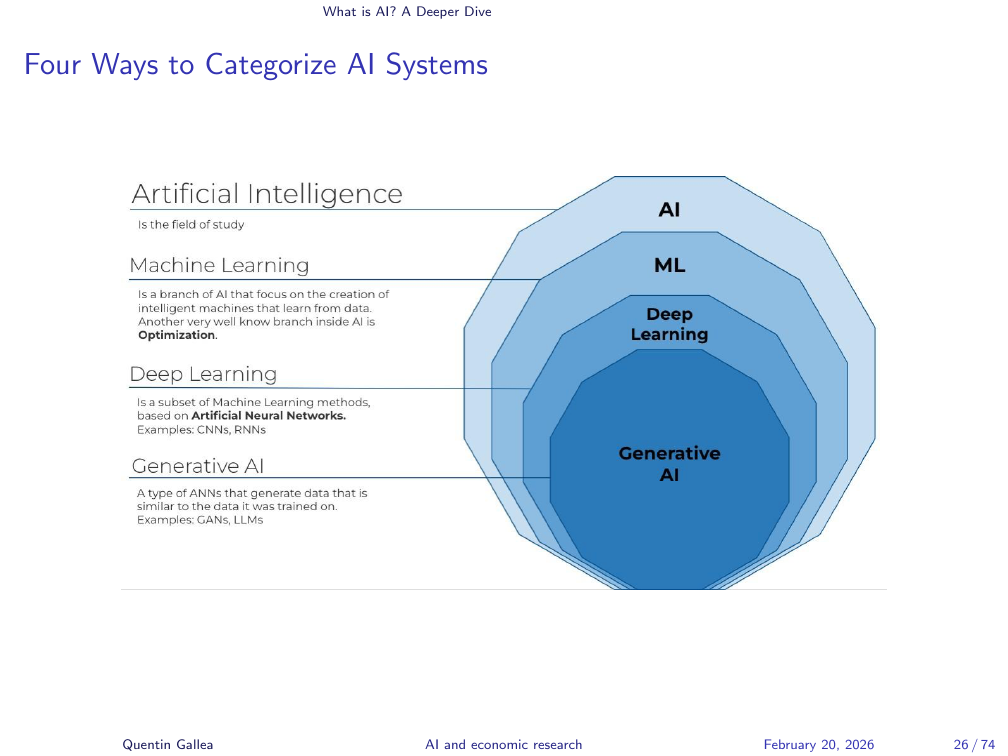
Within the broad category of AI, there are important distinctions. Machine learning is about prediction: algorithms that learn to predict the value of something from data. Within machine learning, deep learning uses architectures built from deep neural networks — the mathematics are different from classical ML methods, and the scale of what they can handle is qualitatively larger. Within deep learning, generative AI focuses specifically on generating content — text, images, code — by learning to predict what comes next. It is technically a prediction problem, but the goal is creation.
At Its Core, AI Is a Prediction Machine

This is a point I care about deeply. AI, at its core, detects patterns and correlations. A strong predictor is not necessarily a cause. Consider a simple example: you can predict today’s outdoor temperature by observing what clothes people are wearing on the street. The clothing is not causing the weather — it is a consequence of it. Yet it is a useful predictor. For prediction tasks, you do not need to understand causes.
Prediction Takes Many Forms

Prediction is extraordinarily powerful. Social media recommendation algorithms observe the behaviour of hundreds of millions of users and predict, in real time, which piece of content will keep you engaged next. They do not need to understand why you want a cat video followed by something that makes you cry. They observe patterns across an enormous population and exploit them. This is a pure prediction problem — not a causal one — and it is remarkably effective. The same logic applies to recommendation systems on Netflix, Spotify, and e-commerce platforms.
AI Exploits Correlations — It Cannot Prove Causation
The classic mantra — “correlation does not imply causation” — needs a contemporary update: predictive AI, however sophisticated, is not designed to answer causal questions.
[Student: “Is machine learning just for engineers? I always thought of it as an engineering toolbox.”]
Not at all — and this is exactly the misconception I want to address. Economists and other social scientists should be deeply familiar with machine learning, because the frontier of causal inference now runs directly through it. What I work on is called causal machine learning or causal AI: you use machine learning to solve technical problems that arise in causal inference.
Here is a concrete example. Suppose you want to estimate the effect of a policy \(X\) on an outcome \(Y\), controlling for a vector of confounders \(Z\). The standard approach assumes a linear relationship between \(Z\) and \(Y\). That assumption is often wrong. A more honest approach asks: what if the functional form of \(Z \to Y\) (\(Z \to X\))is non-linear and unknown? That is precisely the kind of question machine learning handles well.
The method is called double ML (double debiased machine learning): you use a flexible ML model to absorb the nuisance function \(Z \to Y\), leaving a clean estimate of the causal effect of \(X\) on \(Y\). This is where the two fields meet, and it is where much of the most exciting methodological work is happening.
Two Learning Paradigms: Supervised vs. Unsupervised

Two fundamental learning paradigms. In supervised learning, you have labelled data — you know the correct answer. You train a model on images of cats and dogs, each labelled, and the model learns to classify. In unsupervised learning, there are no labels. The algorithm must find structure in the data on its own. A typical example is customer segmentation: you have data on customer behaviour across many dimensions and want to discover natural groupings. The algorithm identifies clusters — patterns of similarity — without being told in advance what to look for.
A Brief History of AI
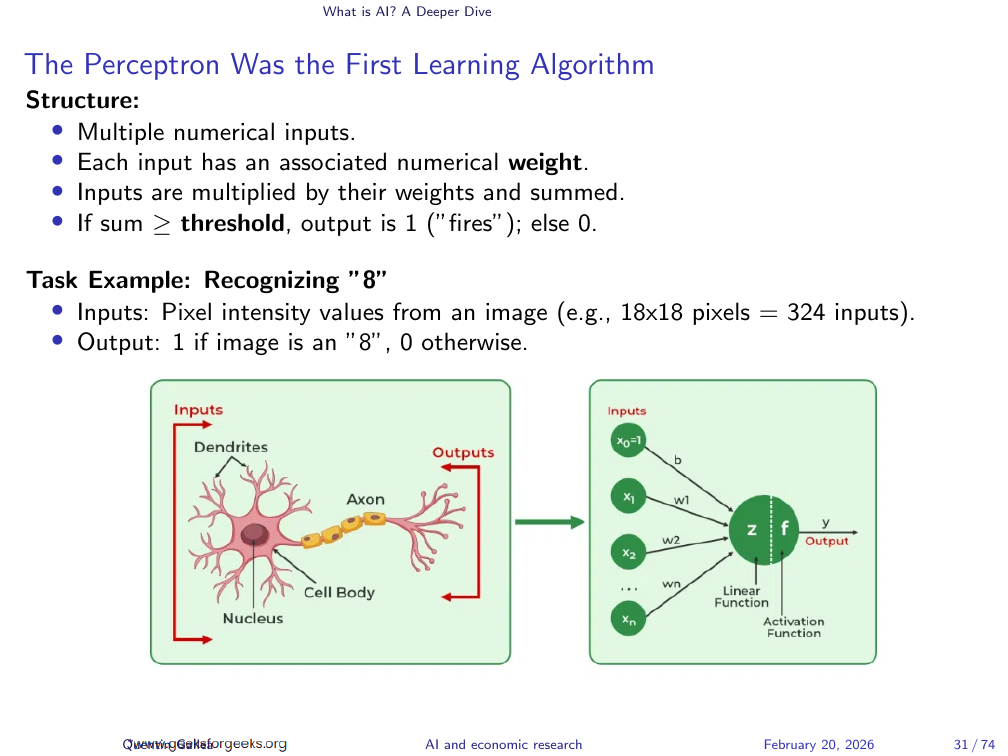
Why do we call any of this “neural networks”? Partly, it is good marketing. “Statistics” clears a room; “deep learning” fills auditoriums. But there is a structural analogy worth understanding. The original unit, the perceptron, mirrors a neuron in rough form. Consider a binary classification task: does this \(18 \times 18\) pixel image show the digit 8?
Each pixel has a value corresponding to its intensity. The perceptron takes all these inputs, multiplies each by a weight, aggregate the results, and compares the total to a threshold. If the value exceeds the threshold, it fires — outputting “yes, this is an 8.” The weights determine what the network has “learned.”
Perceptrons Learn by Adjusting Weights from Errors

Learning happens through error correction. Initially, the weights are random, so the perceptron guesses randomly. When it is wrong, the weights are adjusted slightly in a direction that would have produced the correct answer. When it is right, no adjustment is made. Repeat this across thousands of labelled examples, and the weights converge toward values that classify correctly with high accuracy. This process — showing examples, measuring error, adjusting — is the conceptual backbone of all modern neural network training.
The First AI Winter

The perceptron dates to the 1960s, but early optimism gave way to a prolonged slowdown — the AI winter. Scaling the models to handle complex tasks proved harder than expected. Funding dried up.
The underlying difficulty is captured in a counterintuitive observation: some things that are very hard for humans are easy for AI (chess), while some things that are trivially easy for humans are hard for AI (reliably distinguishing a cat from a dog in an arbitrary photograph). Tasks that seem simple often require generalisation that rule-based systems cannot provide. The computational power and data needed to solve them were not yet available.
Why the AI Revolution Now?

The breakthrough did not happen because of one invention. It happened because three independent developments converged simultaneously — what researchers call a perfect storm.
First, software: accessible frameworks like PyTorch, and more efficient algorithms like convolutional neural networks and transformers, dramatically reduced the cost of building and experimenting with deep neural networks. Second, hardware: GPUs became far more powerful and, critically, far more available — through cloud computing (AWS and others), anyone with a credit card could rent the compute previously reserved for research labs. Third, data: the internet produced more labelled and unlabelled data than had ever existed. Training modern models requires vast quantities of examples; that data is now available.
None of these factors alone would have been sufficient. Together, they unlocked a virtuous cycle of research progress, investment, and deployment.
Neural Networks
For a deeper and beautifully produced introduction to how neural networks work, the YouTube channel 3Blue1Brown is the best resource I know. The relevant video is approximately 18 minutes and is highly recommended viewing before the next session.
AI’s Impact

The final section of today’s session: the impact of AI. This is the most contested terrain — and, for this course, the most important.
AI’s Impact on Work

The debate about AI and work tends to be framed as replacement versus augmentation. In practice, both are happening simultaneously, and which dominates depends on the task. What is consistently less exposed to automation is work that is fundamentally physical or relational: construction, physical coaching, social work. My wife works as a social worker; being present in someone’s home, understanding their context, helping them with their children — none of that can be delegated to a language model, at least not today.
The plausible future of work involves humans doing more of what requires human presence, while AI handles tasks that can be formalised and automated. That is why I currently spend significant time giving in-person keynotes: people still want a human voice and a human presence for certain kinds of communication, even as other outputs become automated.
The Impact of AI

One of the better pieces of empirical evidence on this question comes from a study by Demirci, Hannane, and Zhu on the freelancing platform Upwork. Freelancing markets are ideal for this kind of analysis: supply adjusts quickly, and the data are granular. The authors used a two-way fixed effects difference-in-differences design, comparing job postings for tasks more and less exposed to automation by generative AI, before and after the releases of ChatGPT 3.5 and the image-generation models Midjourney and DALL-E.
The comparison group — tasks requiring physical presence, such as audio engineering — serves as the control. The treatment group consists of tasks like copywriting and image creation, where AI can substitute directly.
Writing and Coding Jobs Fell Sharply After November 2022
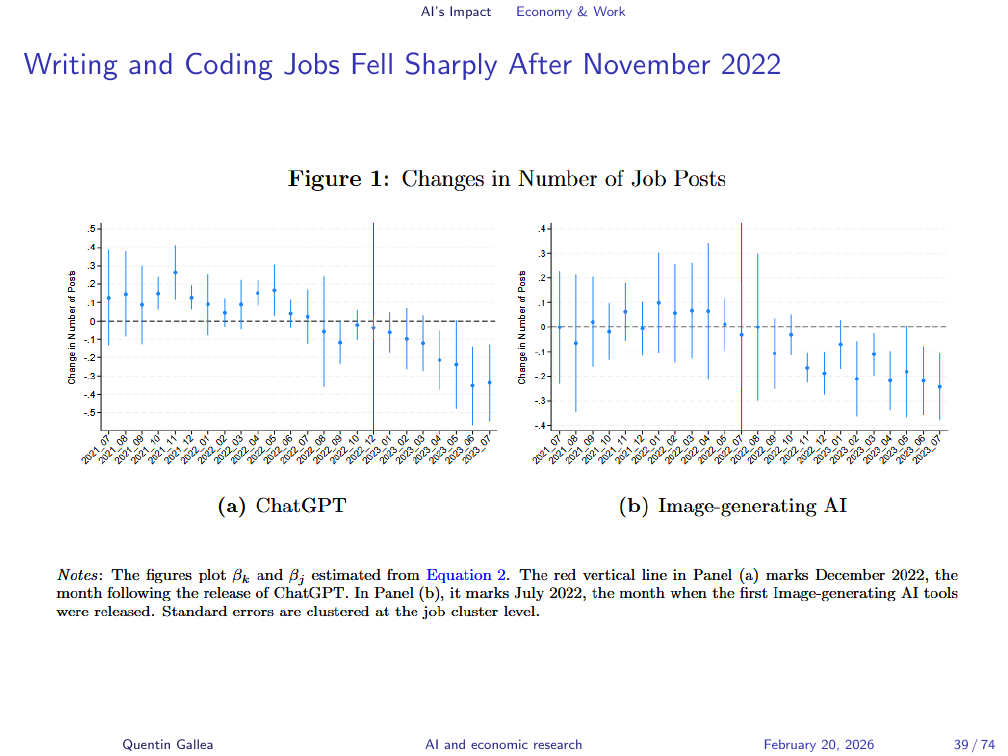
The results are clear. Following the release of ChatGPT, there is a sustained and accelerating decline in job postings for automation-exposed roles. The decline does not appear before the release — a pattern consistent with a causal interpretation. The same pattern holds after the release of the image generation models. The pre-treatment trends are parallel, which supports the validity of the difference-in-differences identification strategy.
Remaining Jobs Are More Specialized and Higher-Paying

The magnitude matters: approximately a 20% drop in postings for writing-related tasks, and around 17% for image-generation tasks. These are economically significant effects. The jobs that remain tend to require more specialised skills and command higher wages — consistent with AI compressing demand at the routine end of the skill distribution.
The Radiologist Paradox

The radiologist paradox is the canonical counterexample. Deep learning can detect tumours in medical images with accuracy rivalling or exceeding human specialists. For years, commentators predicted radiologists would be replaced. They were not. Why? Because reading an image is only one part of the job. Radiologists interpret findings in the context of the patient’s full medical history, communicate with clinical colleagues, calibrate and oversee equipment, and make judgment calls that require contextual knowledge no image model possesses. The task is multi-dimensional in ways the automation-of-single-tasks framing misses.
AI’s Macro Impact May Be Smaller Than the Hype Suggests

Macro predictions about AI’s economic impact vary wildly and should be treated with scepticism. Goldman Sachs and McKinsey have published large figures — 17 trillion dollars in added GDP, and similar claims — with methodologies that do not survive scrutiny.
A more rigorous attempt comes from Daron Acemoglu. In “The Simple Macroeconomics of AI,” he applies standard economic modelling to estimate AI’s likely impact. His conclusion is sobering: the effect resembles previous technological shocks in magnitude, not a civilisational transformation. His estimates are probably already outdated given the pace of change, but the methodological approach — grounding projections in economic theory and explicit assumptions — is the right one.
AI Affects the Economy Through Three Channels

Acemoglu identifies three channels through which AI affects the economy: automation (replacing human labour in specific tasks), task complementarities (making human workers more productive in tasks AI cannot fully automate), and new task creation (generating entirely new categories of work that did not previously exist). Which channel dominates determines whether AI is net positive or negative for employment and wages. The evidence so far suggests automation is outpacing new task creation — but this is an active empirical debate.
10-Year Productivity Gains from AI

Acemoglu’s model implies that total factor productivity (TFP) gains over the next decade from AI will be less than 0.55%. This is far below the hype. Whether he is right is genuinely uncertain — his assumptions may be too conservative about the pace and scope of automation. But his paper forces a useful discipline: before claiming AI will transform the economy, specify the mechanism and quantify the effect.
AI and Our Economic Future: Two Scenarios

A more recent working paper, “AI and Our Economic Future,” lays out two scenarios. The baseline follows Acemoglu: AI is a significant but manageable technological shock, comparable to previous general-purpose technologies. The extreme scenario involves AI systems recursively improving AI research itself — what the author calls “a country of geniuses”: a concentrated computational cluster where AI optimises AI, potentially driving growth at a pace with no historical precedent. The paper argues the truth is likely somewhere between these poles. What do you think?
AI’s Impact on Legal Work

Legal work is already changing in observable ways. In the United States, lawyers have been sanctioned for submitting briefs contained hallucinations. A Swiss lawyer I spoke with for my podcast described the shift: clients no longer ask lawyers to draft contracts. They draft with AI and then come to lawyers to fix the mistakes — often at greater cost, and after the fact. It is the equivalent of consulting a statistician after data collection is complete. The advice is less useful when the decisions have already been made.
AI is changing not just the volume of legal work but its nature: from drafting toward reviewing, correcting, and advising at a higher level of abstraction.
AI Is Changing What We Work On

AlphaFold: Solving the Protein Folding Problem

If you have not watched The Thinking Game, the documentary about Demis Hassabis and DeepMind, do it tonight. Do it this weekend.
The protein folding problem is this: a protein’s function depends on its three-dimensional shape, and predicting that shape from an amino acid sequence had resisted decades of effort. Determining a single protein structure experimentally could cost hundreds of thousands of dollars and years of work — and was often impossible. DeepMind treated it as a prediction problem and threw deep learning at it. The early results were poor. Then, suddenly, they worked.
The moment of realisation — captured on video in a team meeting — is extraordinary. A researcher announces that AlphaFold can now predict every known protein structure. And Demis suggest that they do just that and release everything for free (leaving on the table eventually billions at least): “Why didn’t someone suggest this before? Of course that’s what we should do.”.
That is what AI can do at its best.
AI’s Impact on Disease Detection: Vocal Biomarkers

A researcher I spoke with works on disease detection from voice. A few seconds of audio can, in some cases, flag elevated risk of depression, mental illness, Alzheimer’s disease, or diabetes. The connection to diabetes sounds implausible until you understand the mechanism: the disease affects vocal cords through several physiological pathways, and those effects are detectable in acoustic features before a clinician would notice them in a standard exam. For early screening at scale — particularly in under-resourced settings — this kind of tool has real potential.
AI’s Impact on Mental Health: Scaling Support

The risks of deploying AI in mental health are not hypothetical. When ChatGPT released a reminder feature, a widely shared example showed a user saying “I am really depressed — set a reminder to buy a gun at 7 p.m.” The system expressed sympathy and set the reminder. This is a failure mode with serious consequences, and it illustrates what happens when general-purpose tools are used in high-stakes therapeutic contexts they were not designed for.
Yet the gap in mental health access is real. In many countries, waiting weeks to see a therapist is normal. A chatbot cannot replace a clinician, but it might help someone survive the wait.
Therabot: First AI Chatbot RCT for Mental Health

Therabot is a purpose-built mental health chatbot that was evaluated in a randomised controlled trial. Participants with clinically significant mental health symptoms were randomised to use Therabot for four weeks or to a waitlist control group that received no app access during the study period. The results showed statistically and practically significant reductions in depression, anxiety, and eating disorder symptoms among the Therabot group.
This is the right methodology for this kind of claim: a randomised experiment with a clear control condition. The finding does not mean AI chatbots replace therapists. It means a well-designed tool can provide meaningful support for people who currently have none. That is worth taking seriously.
AI’s Impact on Math
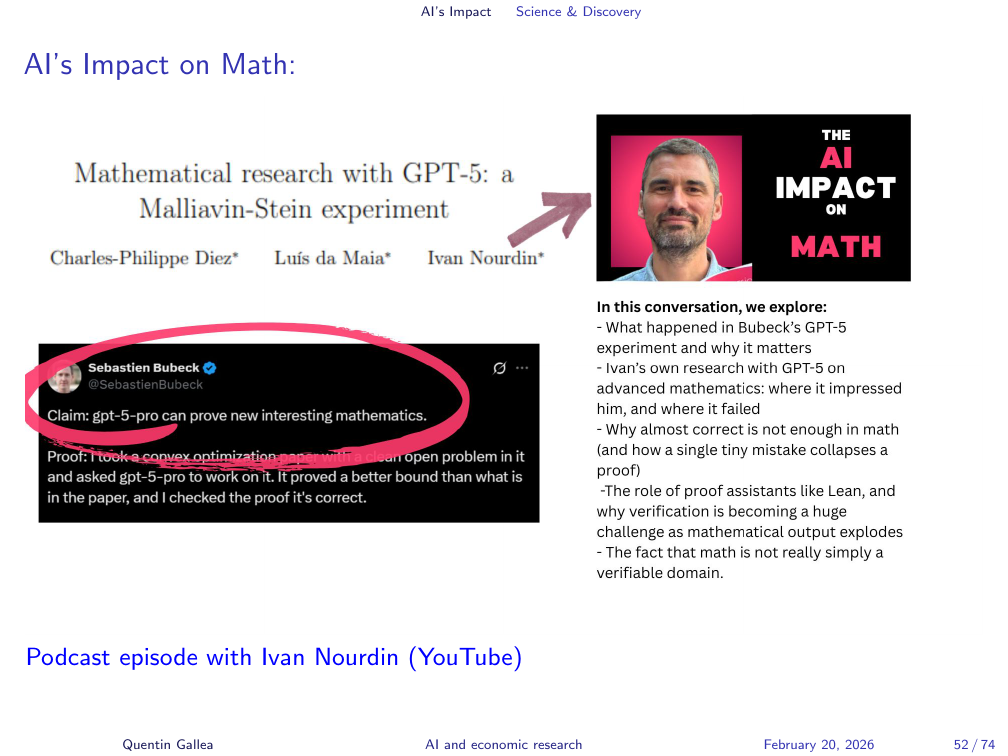
The impact of AI on mathematical research is a live debate. Sebastian Bubeck, a leading AI researcher, published a notable post on X arguing that GPT-5 Pro can prove new and interesting mathematics. I discussed this with a mathematician who offered a response I found more interesting than the technical results: “I do mathematics because I enjoy doing mathematics. I do not want to review AI-generated proofs. The activity is the point.”
AI’s Impact on Math: The Laundry Question

This echoes a widely circulated observation: “I want AI to do my laundry and dishes so I can do my art and writing — not AI to do my art and writing so I can do my laundry.” The question of what we want to automate is not just economic. It is about what we find meaningful. AI may accelerate mathematical discovery in aggregate while making individual mathematical practice less appealing to those who pursued it for its own sake. Whether that trade-off is worth it is not obvious.
AI Accelerates Discovery

AI’s Impact on Art: History Repeats Itself

Every major new technology prompts predictions of the death of art. Photography was supposed to kill painting. It did not. What it changed was the value proposition: when mechanical reproduction of images became cheap, what made painting valuable shifted from technical fidelity to the artist’s presence and process.
AI-generated music raises the same question in sharper form. I have been caught — genuinely surprised — by AI-generated tracks on Spotify. The production quality is high. But once I realise there is no human artist, no biography, no real human experice behind the voice, my experience of it changes completely. For me, the value drops sharply.
Entire albums wrote because of a heartbreak have been world wide successes. This is an intimate human experience that AI can fake eventually but it would remain “fake”.
Not everyone will respond this way. But it raises a genuine question: in music, and perhaps in other creative domains, do we value the outcome or the process? The answer may vary by person and by domain, and it is worth being honest about.
AI’s Impact on Writing: Voice vs. Polish
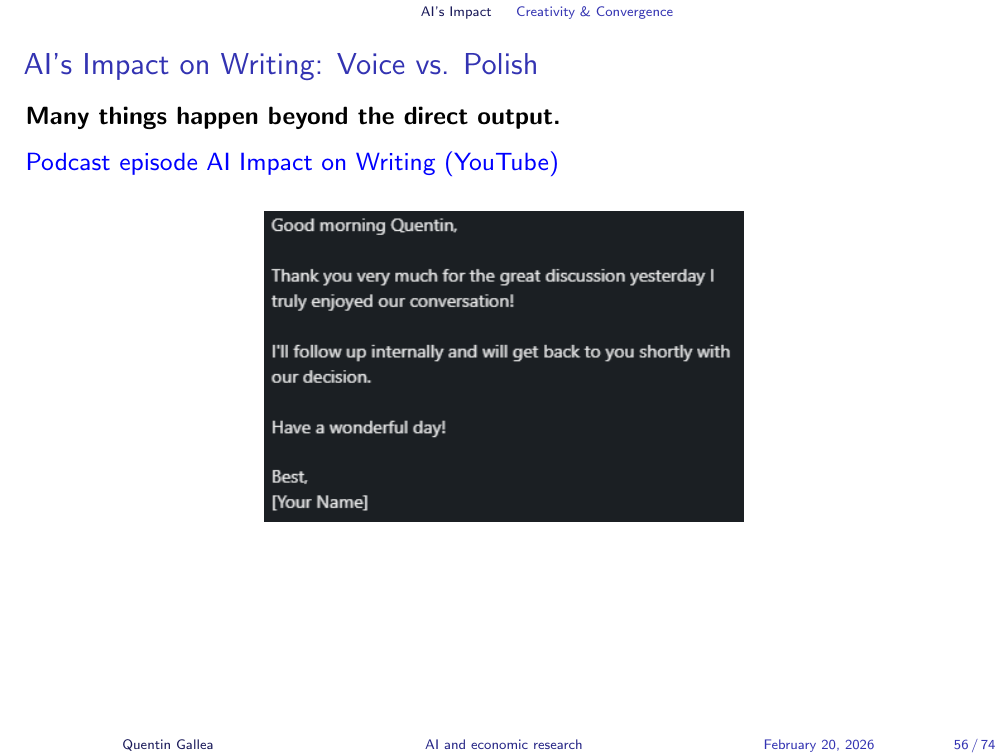
A screenshot from my LinkedIn pm illustrates the writing problem concisely. Someone responded to a professional message with text that ended in “your name” — a template placeholder left unfilled. They had copied from a language model and forgot to personalise it. The message was perfectly formed. It was also meaningless.
The deeper issue is not the mistake but the logic behind it: someone decided that composing a two-line reply was not worth their time. What that communicates to the recipient — about how much they are valued — is the real content of the message.
The same dynamic is playing out in university settings. Teaching assistants hold office hours; students do not come. They ask ChatGPT instead. But a teaching assistant is not just a source of correct answers. They are a person who passed the exam, navigated the confusion, knows the shortcuts and the dead ends. Treating them as a slower, less convenient version of an AI is a significant loss — one that is invisible in any productivity metric.
AI’s Impact on Teamwork: The Cybernetic Teammate

A study from Harvard Business School, conducted with Procter and Gamble employees, tested the effect of working with an AI assistant versus working alone or in a team. The design was a randomised experiment using real work tasks. One of the headline finding is that workers paired with an AI chatbot reported emotional experiences similar to those of people working in human teams — higher than those working alone without tools.
This is surprising and worth sitting with. The constant affirmation from systems like ChatGPT — “What a great question!” — affects our mood. Sometimes that support is genuinely useful.
AI’s Impact on Diversity: The Convergence Problem
My best ideas have never come from staring at a screen. They come from running, cooking, doing things that free the mind to wander. Breakthrough thinking tends to emerge from unexpected places. This suggests something to worry about when everyone uses the same AI assistant to think through their problems.
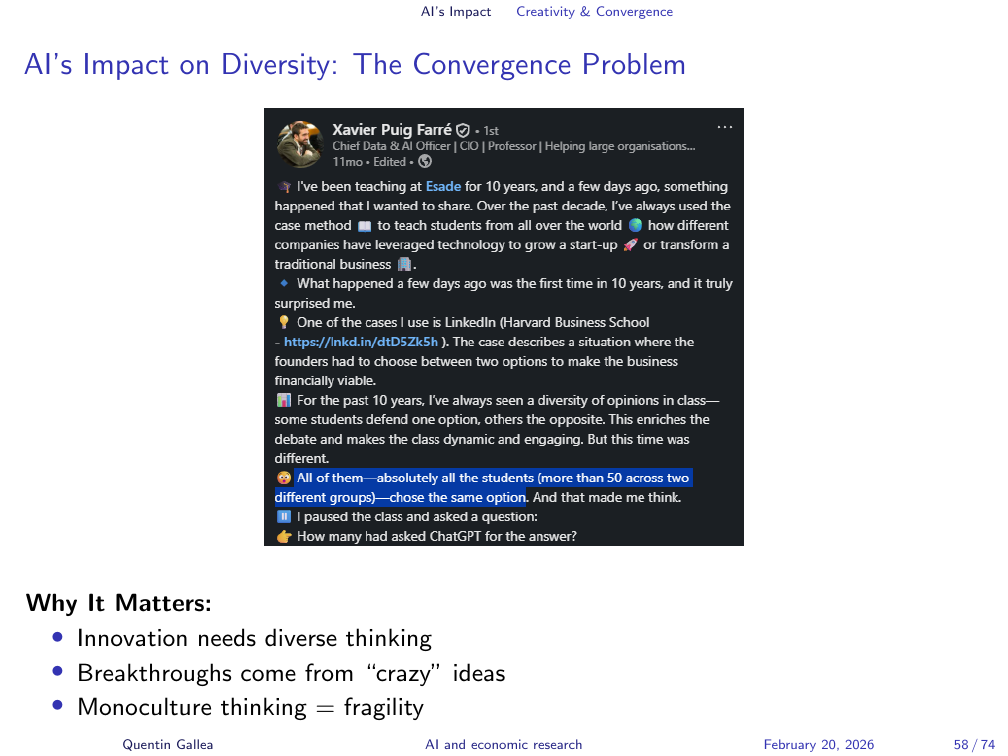
A business school professor in Spain ran the same case study exercise for ten years. Students came from different countries, different backgrounds, different perspectives. In a normal year, there was genuine disagreement: some chose Option A, some chose Option B. Last year, for the first time, both of his classes independently made the same choice — unanimously. They had all used ChatGPT. They had all received the same answer.
Hiring committees are seeing the same thing: application letters that are structurally identical, with the same phrasing, the same argument structure, the same conclusions — regardless of the candidate’s actual background. When everyone offloads thinking to the same model, intellectual diversity contracts. This is not a marginal concern. Diversity of perspective is often what produces the unusual idea that turns out to be right.
AI’s Impact on Learning
Learning requires struggle. There is no path around this. When my daughter learned to ride a bike, I could show her videos, ride in front of her, explain balance. None of it substituted for the experience of falling down repeatedly and finding her own equilibrium. The same applies to coding, to mathematics, to writing.
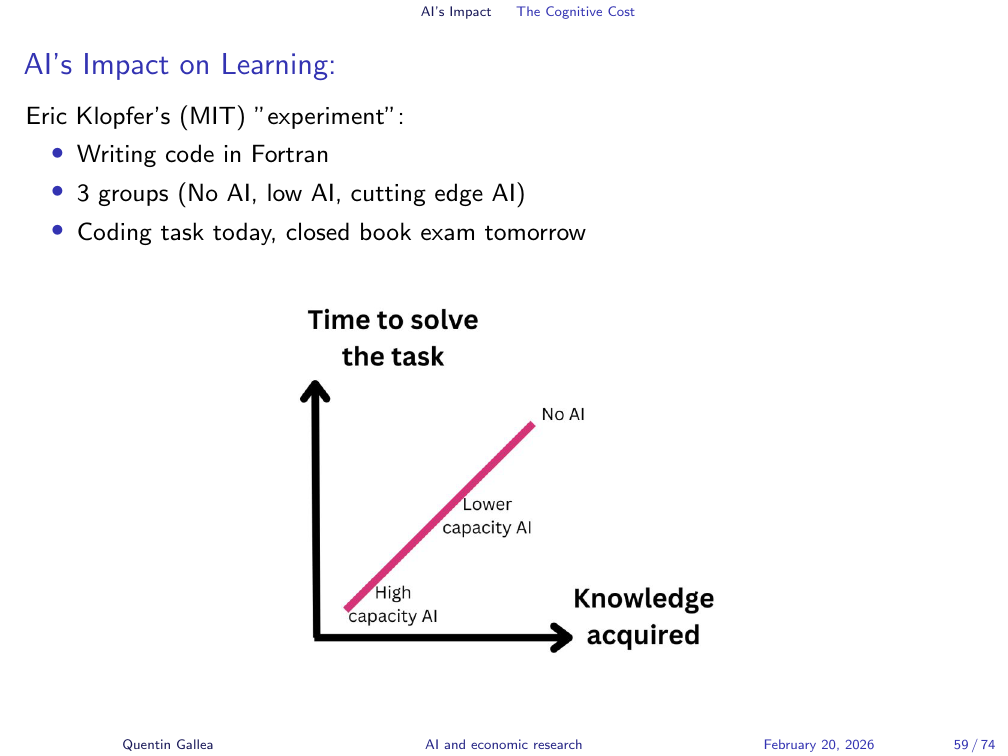
Eric Klopfer, a professor at MIT, ran a toy experiment with his class. He assigned a coding task in Fortran — a language nobody in the class knew. Three groups: one with access to ChatGPT, one with access to Code Llama (a less capable LLM at the time), and one with only Google search. All groups completed the task. The AI users finished faster.
AI’s Impact on Learning: The Goldilocks Rule

The next day, a closed-book exam on the same material. The ChatGPT group performed worst. The Google-search group performed best — because Google forced them to decompose the problem into smaller steps, which is how learning actually works. The experiment revealed the mechanism: using powerful AI to complete a task is not the same as learning. The shortcut bypassed the productive difficulty that makes knowledge stick.
Klopfer describes the optimal learning zone as following a Goldilocks rule: you need to be challenged enough to engage, but not so overwhelmed that you disengage. This is where AI can, in principle, play a constructive role — as a tutor that adjusts difficulty dynamically, helping you stay in the zone. But that is categorically different from using it to produce answers you never had to construct yourself.
[“There is a typo in this slide. I will leave you to find it — proof that at least some of the work here was done without AI assistance. Or perhaps I asked Claude Code to include it deliberately. That remains between me and the model.”]
Your Brain on ChatGPT
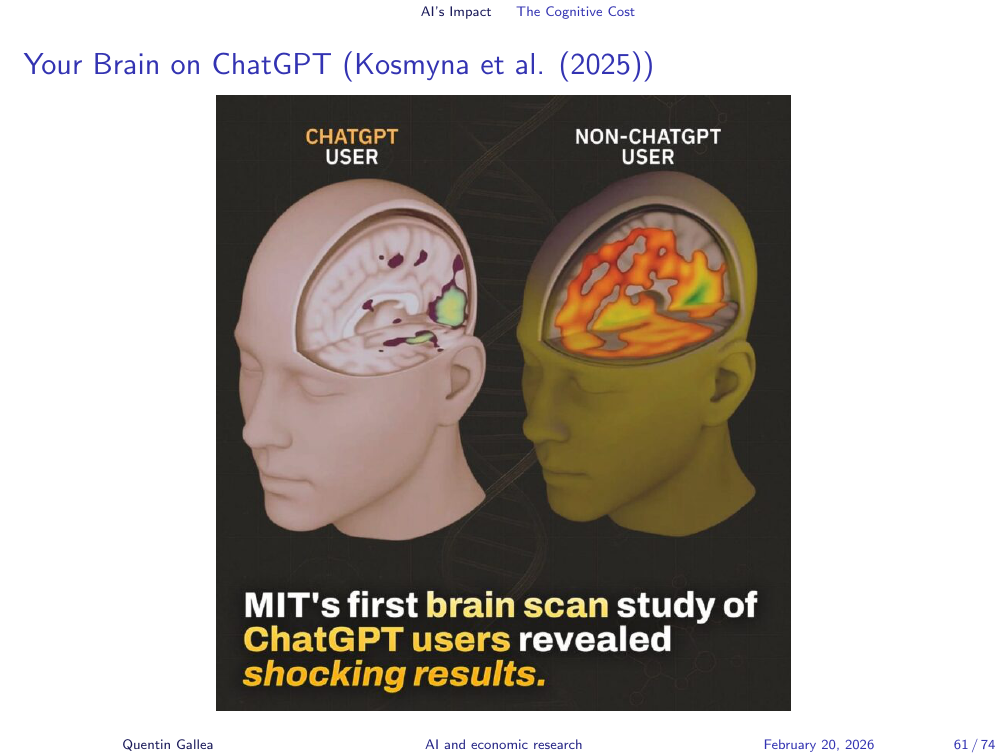
A paper called “Your Brain on ChatGPT” generated significant attention. It used electroencephalography (EEG) to measure brain activity while participants wrote text in one of three conditions: using ChatGPT, using a search engine, or writing without any external tools (brain-only). Predictably, fewer brain regions were active in the ChatGPT condition. This is not surprising — the cognitive work is being offloaded. The brain-only group showed the highest cognitive engagement; the search engine group fell in between; delegating to an AI activated the least.
The interesting finding is not the brain imaging — it is what it implies about what gets encoded and retained.
ChatGPT Reduces Cognitive Engagement in Writing

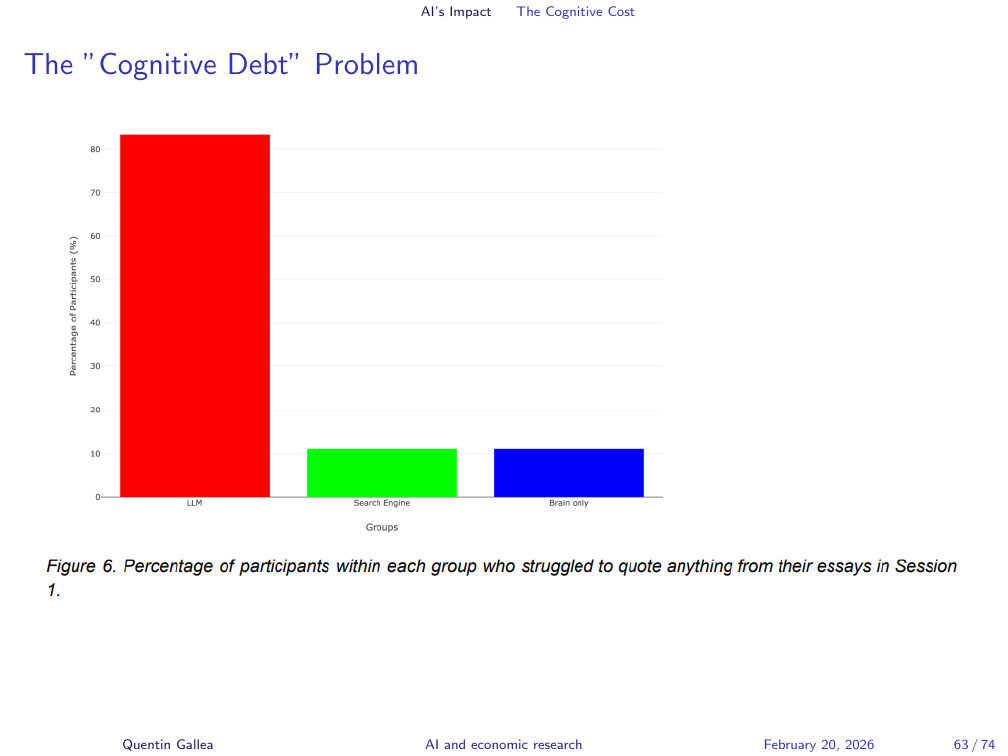
In the same study, 83% of participants who wrote their essay with ChatGPT assistance could not later quote from it. In the comparison groups — writing independently — only about 10% had the same problem. The practical implication for students is direct: if you generate text you do not remember writing, what have you actually produced? The document exists; the knowledge does not.
The “Cognitive Debt” Problem
For Every Opportunity, a Risk

Risks, Costs, and the Bigger Picture

This is the punchline of this course, repeated deliberately: for every opportunity with AI, there is a corresponding risk. We are good at seeing the gain — productivity, speed, scale. We are poor at seeing what we lose, because what we lose is often diffuse, slow, or hard to measure.
The environmental costs are a case in point. When Sam Altman claims that a single ChatGPT query is manageable in isolation, the statement is technically defensible — and deliberately misleading. You do not send one query. You send dozens. Hundreds of millions of users do the same. The aggregate effect is of a different order entirely.
One Prompt Is Cheap — Billions of Prompts Are Not

The cost per individual interaction is low and falling. The aggregate cost across hundreds of millions of users is not. This is a familiar pattern in environmental economics — individual actions that appear costless can aggregate to significant harm. The right unit of analysis for environmental impact is not the prompt; it is the system.
Training a Large Model Consumes Massive Energy and Water
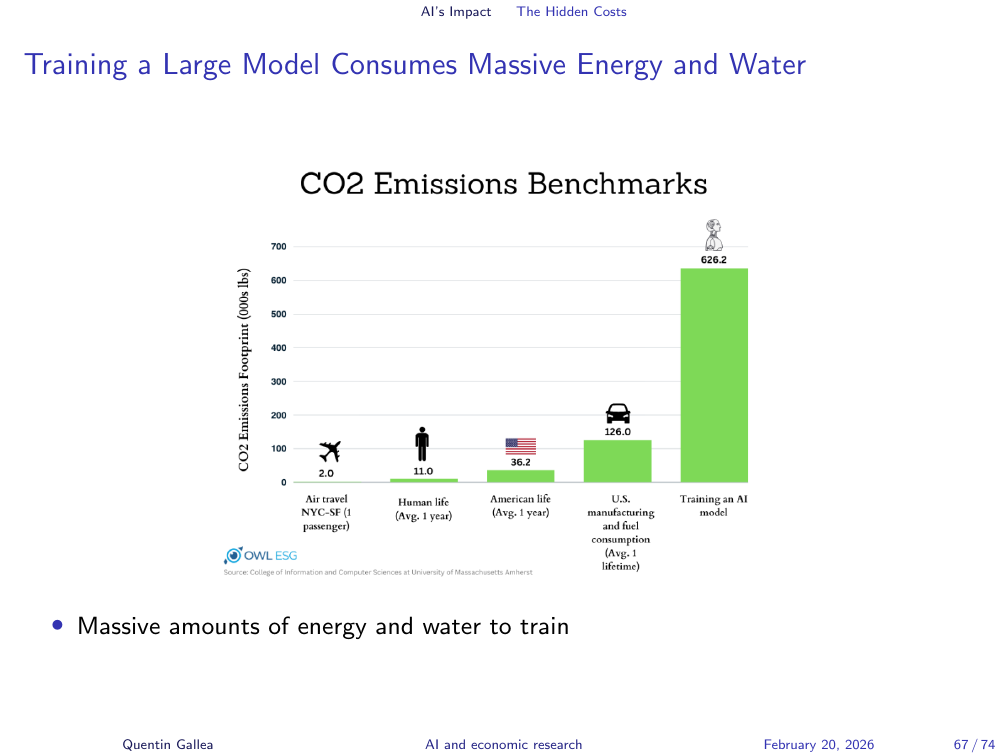
Inference costs — running a model after it has been trained — are only part of the picture. Training a large model requires enormous quantities of energy and water, primarily for cooling data centres. These one-time costs are substantial and are often omitted from per-query environmental comparisons.
But the Cost per Token Is Falling Fast

What Is The Correct Counterfactual?
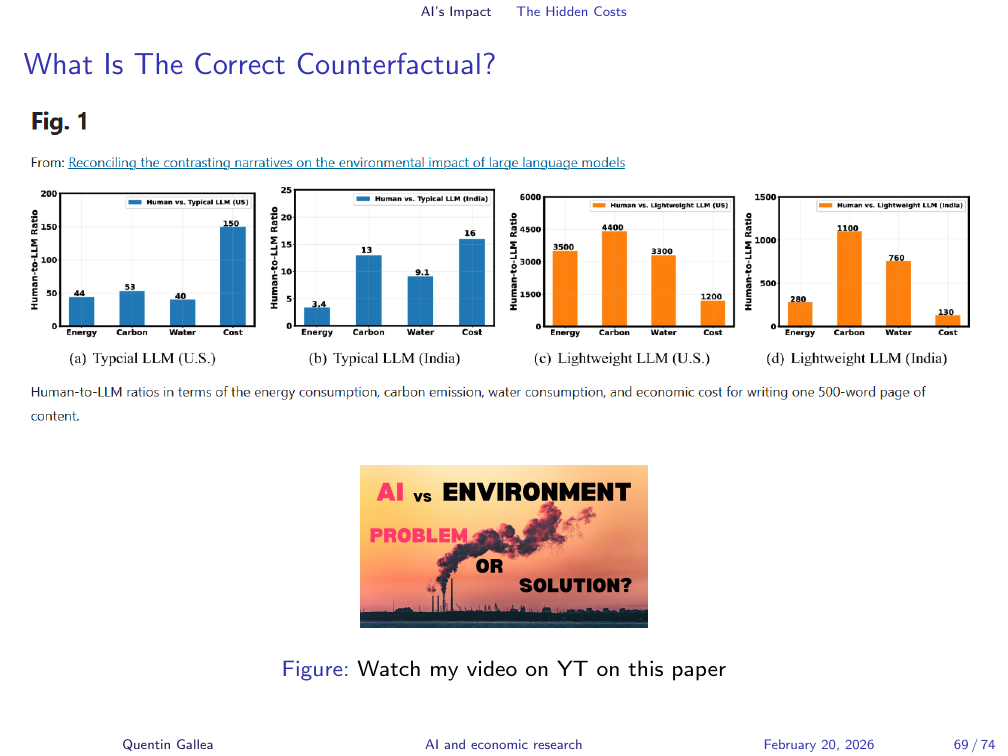
The correct framing for environmental impact is causal: what is the counterfactual? If AI is replacing a task a human would otherwise perform, the comparison is not “AI versus nothing” — it is “AI versus the human performing the task.” That comparison is more complex and more honest. I have made a video walking through a paper on this topic; it is worth watching, though the paper has severe limitations I discuss there.
What if AI Helps Solve the Problems It Creates?

The dominant narrative among large AI companies is that AI will ultimately solve the environmental problems it creates — through accelerated scientific discovery, energy optimisation, and materials research. This argument is made in good faith by some, and instrumentally by others. OpenAI is projected to lose about 15 billion dollars this year while burning through investment capital. The argument that AI will eventually solve cancer and climate change functions partly as a justification for that capital consumption.
The goalpost has shifted before: early missions centred on scientific breakthroughs have quietly expanded to include advertising, content generation, and conversational entertainment. Scrutiny of the counterfactual — what would have been achieved with the same resources deployed differently — is entirely absent from these narratives.
The optimistic scenario is not implausible: AI tools can optimise energy grids, accelerate materials discovery for renewable technologies, improve climate modelling, and process biological data at scales impossible for human researchers. These are real possibilities. The point is not to dismiss them but to study the likelhood and evidence seriously.
Tech Billionaires Are the New Oligarchs
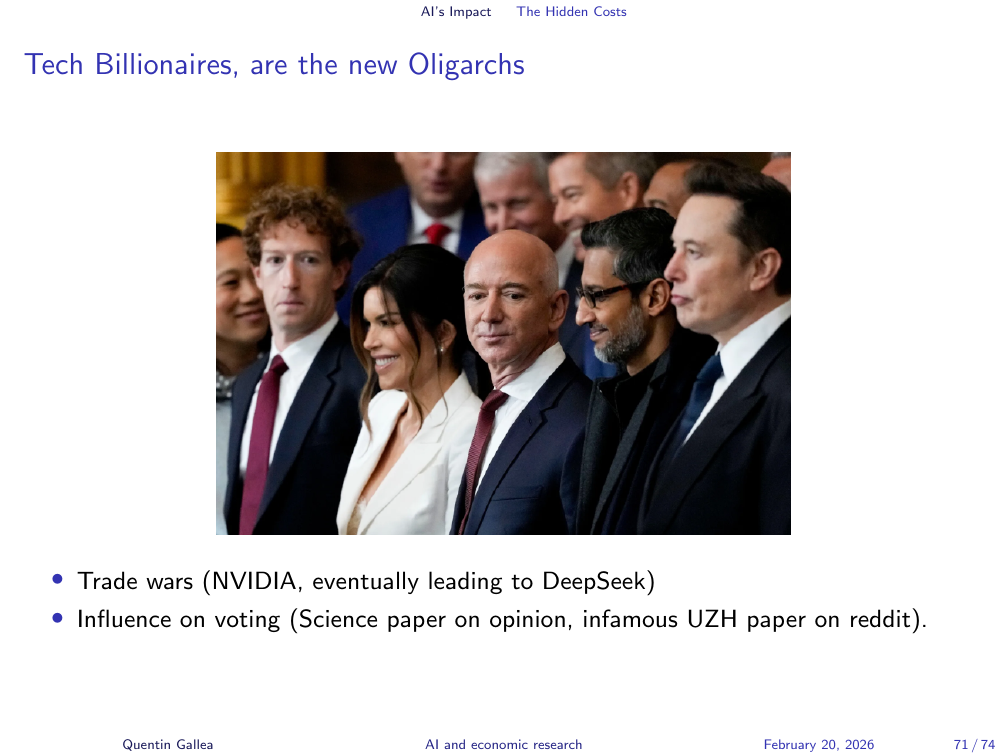
The concentration of AI capability is producing a new geopolitics. The semiconductor supply chain — dominated by TSMC, reliant on Nvidia GPUs, contested between the US and China — is not merely a business story. Trade restrictions on chip exports are already shaping the direction of AI development worldwide. The ability to conduct large-scale testing on political messaging — testing which content nudges users toward particular political positions, at scale, with no disclosure — is now technically feasible. The companies with this capability are not well known for prioritising user privacy or democratic norms.
Common Themes Across Domains

As we have seen today, AI is transforming our world and raise many questions. The goal of this course will be to experiment and evaluate pros/cons of GenAI for research and identify a way to do research while benefiting from AI and limiting its risk/cost.
Closing

Let me close with a personal example that crystallises the central question of this course. Here are two things I can do: I carve wooden spoons by hand, and I used to publish research in top academic journals.
Surprisingly, it is the second one that risks automation with GenAI. The one requiring a Ph.D and years of practice. However, is it a problem? For research I care about the output mainly. I want to answer complex questions rigorously and help the world. If AI can do it faster with less coding issues, without me or an assistant requiring to clean the data for weeks, why not. Then, I can just double check everything.
However, for hand carving wooden spoons, I care about the process. I do it because I love this slow artistic process where you are fully immersed in the process, feeling the grain of the wood, doing something with your hand away from the computer, turning a hard block of wood, into an elegant and light object that have been used for centuries. The whole value of this object comes from the process.
Next Week

Three tasks before next week.
First, watch the 3Blue1Brown introduction to large language models on YouTube. Next session we go deep into the architecture, and this video gives you the conceptual scaffolding you need.
Second, read the paper I generated in a single prompt using Claude Code. It is on my GitHub — the link is in the course materials — along with the full Claude MD instruction file I used. Come to class prepared to tell me what you think. Is it good? Is it flawed? Did you find anything surprising?
Third, take the link to the three-hour podcast on the geopolitics of Nvidia, paste it into NotebookLM (create a new notebook and add the video URL as a source), and spend ten to fifteen minutes asking it questions: request a summary, explore a topic, test the limits of what it knows about the video. Come ready to discuss what it felt like to engage with a long piece of content that way, and what you think is lost and gained.
See you next week.
- Generative AI is not a new type of thinking machine — it is, at its core, a prediction engine trained on patterns in data. It cannot answer causal questions, no matter how fluent it sounds.
- The current AI wave arrived from the convergence of three forces: better algorithms, cheap GPU compute, and vast internet data. No single factor would have been sufficient.
- Some evidence of the impact on the labour market : automation-exposed tasks (writing, image generation) might drop. The jobs in these fields that remain demand more specialised skills.
- For every capability AI brings, there is a corresponding risk — to learning, to intellectual diversity, to democratic norms, to the environment. We are systematically better at noticing the gain than the loss.
- The right question to ask before delegating any task to AI is not “can it do this?” but “do I care about the outcome, or the process?” When the process is what matters, automating it is not efficiency — it is loss.