Reading Scientific Research
Session 04 — GenAI & Research
This session covers how to read scientific papers effectively — both with and without AI tools. We start with the traditional three-pass method for evaluating research, then explore how tools like NotebookLM can augment each stage of the reading process. The central message: reading research is not just about extracting information — it trains your writing, sharpens your critical thinking, and builds instincts that no LLM can develop for you.
Introduction and Warm-Up

Enjoy the Process
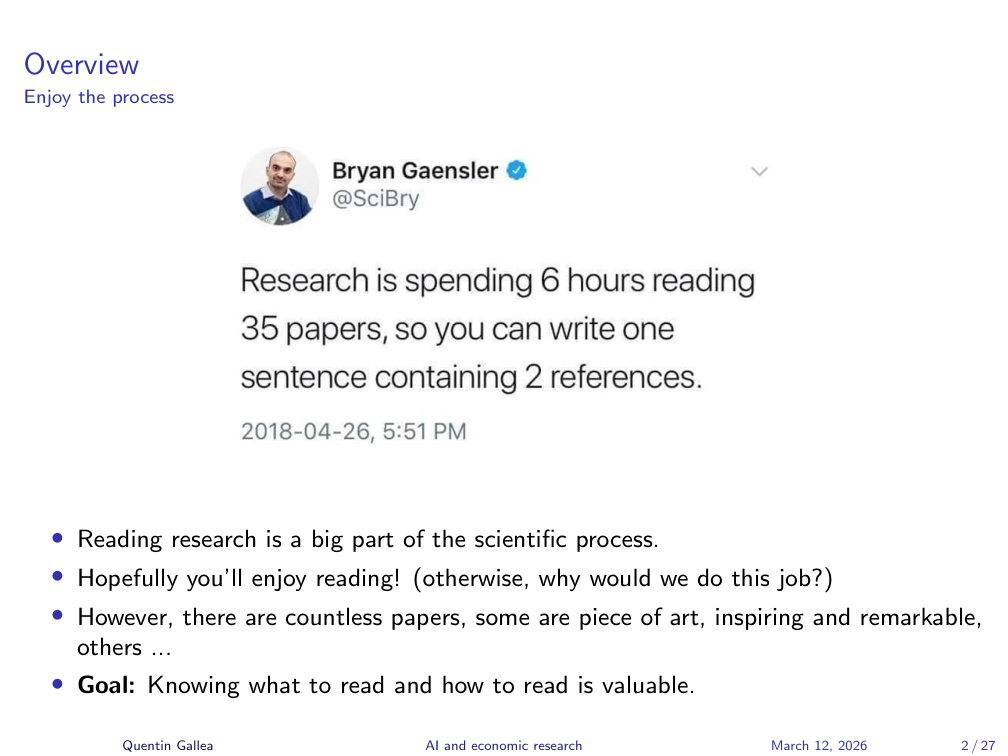
This session follows a slightly different structure: a quick warm-up, a focused lecture, then hands-on practice with a debrief. The main purpose of this class is to experiment and discover answers together — good guidelines, applications, tips, and tricks for using GenAI in research.
As a warm-up, students shared recent AI use cases. One student described using an LLM to translate official documents for a bank. The translation quality was strong — it even knew not to translate proper nouns like country names, which a simple translation tool would have changed. Compared to tools like DeepL, LLMs tend to translate more pragmatically, taking the full document context into account rather than translating sentence by sentence.
Another student shared that using Claude’s Cowork feature to organize files and folders has been transformative. You can ask it to generate files, rename them, and save them in the right place. For anyone juggling work and studies, this kind of automated organization is a real time-saver. The instructor also demonstrated Cowork by showing how he used it to organize tax documents — throwing in PDFs with unclear names, and having Cowork read, rename, and sort them into a structured folder, complete with a checklist and to-do list.
Why This Skill Matters

Reading is a big part of scientific research. You spend enormous amounts of time reading papers, getting to know them inside-out, and then sometimes add just one sentence to your final thesis. So hopefully you enjoy the process of reading — because it is the process, not just the output, that matters.
When you read, you also learn a lot about writing. Reading top papers by top scientists shows you how to frame sentences, use precise terminology, and communicate impact. These things are subtle, and LLMs might get them wrong. For example, in causal inference the distinction between an “association,” a “predictive model,” and an “instrumental variable” must be incredibly precise. Reading well-written papers trains your instinct for this.
Of course, you cannot read everything. Sometimes you just want a specific answer: what was the identifying strategy? What data set did they use? Here, LLMs are powerful — they can extract the answer quickly so you can decide what deserves a deeper read.
Beyond academia, understanding research matters in everyday life. Misinterpreted research in the news is everywhere — reporters and politicians claiming “research has shown” when, in the vast majority of cases, they are confusing correlation with causation.
A Paper Is Not the Truth
Just because something is published in the American Economic Review, Science, or Nature does not make it the truth. People make mistakes. There have been scandals of data manipulation by top scholars. Sometimes the terminology is simply too aggressive or misleading. Even top research has limitations, shortcuts, and heroic assumptions that deserve scrutiny — even work by someone like Acemoglu can contain identifying assumptions you might strongly disagree with.
The same applies in any classroom. Claims should come with evidence, and the right response to uncertainty is to convey it honestly — using language like “it tends to,” “there’s some evidence,” or “this research has shown” rather than stating things as absolute fact.
Today’s Agenda

The session structure: first, traditional methods for reading a paper without GenAI; then, how GenAI can augment the reading process; and finally, practice and debate.
Part 1: The Traditional Method
With the motivation established — reading matters, papers are not gospel, and there is too much to read — we turn to a structured approach for tackling scientific papers efficiently.
Three Different Levels

Reading a scientific paper is not like reading a book from first line to last. It has a very different structure, and there are different depths at which you can engage: a quick pass, a deeper dive, and a full analysis when you really want to own the research.
Before Reading: Define Your Goals

Before diving in, clarify your goal. Following the framework from Carey et al. (2020), “Ten Simple Rules for Reading Scientific Research,” your purpose might be: learning what is new in a field, understanding a specific method, or answering a precise question. This first quick pass also serves as a filter — there is too much research out there, and you need to decide quickly whether a paper deserves more of your time.
Quality Screening
Before you even start reading, a few quick checks can save you from investing time in low-quality work. These signals are imperfect, but together they paint a useful picture.
Quality Screening Overview

Before even opening a paper, a quality screening is useful. The metrics involved — journal, authors, year, citation count — are imperfect, but they provide a helpful signal.
Journal and Impact Factor

The journal is a useful first signal. A paper in a top-five economics journal has been screened by leading scholars who ensured it meets high standards of quality and relevance. The system is not perfect, but publication in a top journal is a strong signal.
In economics, the top five journals (AER, Econometrica, JPE, QJE, REStud) are extremely competitive. General science journals like Science, Nature, and PNAS are also prestigious but differ in format, length, and reporting style. Be careful with sub-journals: Nature Scientific Reports (impact factor ~3.8) is a completely different publication from Nature (impact factor ~50), even though both live on nature.com. The sub-journal name appears in small text below the title — easy to miss.
The impact factor (IF) measures the average number of citations per paper published in a journal over the previous two years. A QJE paper receives about 19 citations on average; Nature about 50. However, IF varies enormously across fields — energy research and medicine naturally produce higher citation counts than niche economics subfields. So IF is a useful proxy, but it must be interpreted within the context of a discipline.
Journal quality rankings like the ABS list can also help. Journals rated four stars are genuinely top-tier. Anything below three stars is lower-tier and may not have gone through equally rigorous review. Researchers typically aim for the best journal first and work downward — so a paper in a weak journal may be there for a reason.
Citations

Citation count is another noisy but useful signal. A ten-year-old paper with only three citations is not a great sign. A paper with thousands of citations is almost certainly worth reading. Of course, citation counts depend on the field, the topic’s breadth, and how long ago the paper was published — a recent paper cannot be expected to have many citations yet.
Note that citations can be negative — a paper might be cited precisely to be criticized. But heavily cited papers tend to be cited because they are useful, not because they are bad. This matters especially for seminal work, which by definition attracts a large number of citations.
Publication Year

The publication year tells you different things depending on the time horizon. Recent papers (the last few years) show where the field is heading right now. Their conclusions often flag open questions — very useful for thesis ideas. Papers from about ten or more years ago are usually where you find the foundational work. Really old papers (20–30+ years) are typically cited for seminal contributions or for specific techniques (e.g., the original instrumental variable paper).
How far back is relevant depends on the field. If you study the impact of GenAI, papers from ten years ago cover completely different models — they may be irrelevant to current questions.
The Three Passes
With quality screening complete, we move to actually reading the paper. The three-pass approach gives you a structured way to go from a two-minute scan to a full-day deep dive — investing more time only when the paper warrants it.
Pass 1: Quick Overview

The first pass is about getting the gist quickly. Read the title, the abstract, and if the paper passes the quality check, skim the introduction and conclusion. The introduction typically contains an overview of the whole paper — literature positioning, methodology, the main result. The conclusion highlights limitations and opens new questions.
In practice, even within the introduction, you do not need to read every word. Read the first sentence of each paragraph, then stop on sections that matter to you — the data set, the econometric strategy, the specific result. Look at figures and tables too: they are designed to illustrate the paper’s punchline.
Be mindful that there is a lot of marketing in research. Titles are designed to be catchy and memorable: “The Jagged Technological Frontier,” “Make Trade Not War,” “Saving the World from the Couch.” Abstracts are crafted to be impactful. This is not dishonest — it is how academic communication works — but it means you need to go beyond the title and abstract to judge substance.
Pass 2: Deeper Dive

In the second pass, you read through the entire paper, focusing on methodology, data, and assumptions. In empirical economics, this means understanding the sample, the coverage, the identifying assumptions — the conditions under which a causal claim holds. These assumptions are often untestable, so you have to be convinced by the narrative.
After this pass, you should be able to answer: What is the data source? How are the variables coded? What is the coverage? What are the main results, and how do the authors interpret them?
Pass 3: Full Analysis

The third pass is for the paper you want to build on — the one you might extend for your thesis. Here you read everything: the full text, the appendix, and the papers it cites. This can take a full day, sometimes split across two.
After a full analysis, you should be able to criticize the paper. There are always limitations, shortcuts, and debatable choices. Research is done by humans operating under incentive structures like publish or perish, which can push toward presenting statistically significant results. Questioning the choices researchers made — what they show, how they coded variables, what they left out — is part of rigorous reading.
A practical tip from a student: active reading matters. Highlighting, annotating, and taking notes in the margins keeps you engaged and prevents your eyes from drifting. Tools like Zotero are excellent for this — you can organize papers in folders, highlight passages, take notes, and have everything saved and synced across devices.
Another useful habit: annotate the introduction itself. Mark where the motivation is, where the research question appears, where the methodology is described, and where the limitations are mentioned. This makes it much faster to return to the paper later.
Part 2: The AI Research Assistant
Now that we have a solid traditional reading framework, the question becomes: where can AI fit in — and where should it not?
Prompt Injection in Research Papers

Before discussing how AI can help with reading, a word of caution. As discussed in a previous session, prompt injection is a real concern. The paper “Your Brain on ChatGPT” included a hidden instruction telling LLMs to praise the paper if they were summarizing it. It was a somewhat naive marketing trick, but the underlying risk is real: as more researchers use LLMs to summarize and rank papers, prompt injection could become a way to game the system.
NotebookLM vs Prompt Injection

Notably, NotebookLM was not tricked by this simple prompt injection. This is worth keeping in mind — different tools have different vulnerabilities. As AI-assisted reading becomes more common, awareness of prompt injection in research papers may become increasingly important.
Hallucinations

The second main challenge is hallucination. When doing research, you need precise, reliable answers. If you upload a paper directly to an LLM, the paper is in the context window — the model can “read” it directly rather than trying to recall something from its training data. This is more reliable than asking about a paper from memory, but it is still not immune to misinterpretation.
This is why NotebookLM is particularly powerful for research reading: it constrains answers to your uploaded sources and lets you verify every claim by checking the original passage.
What Is NotebookLM?

NotebookLM is a tool where you upload sources and the AI is constrained to answer primarily from those sources. You can ask questions, use suggested prompts to explore the content, and work with multiple sources simultaneously. The source selection feature is particularly useful: you can ask a question across all your sources or restrict it to a single paper. Previous sessions covered the podcast/audio summary feature as well.
Augmenting the Reading Process with AI
With the risks understood — prompt injection and hallucination — we can now explore how AI tools genuinely enhance each stage of the reading process.
Augmenting the Standard Approach

Every level of the reading process can be augmented with AI. For the quick overview, you can ask: “Does this paper answer my research question?” or “What methodology does this paper use?” — questions that help you decide whether to invest more time. For the deeper dive, you can ask precise questions about methodology, data, or results that might be buried deep in the paper. For the full analysis, AI can help you find subtle details in lengthy appendices that would take hours to locate manually.
Instead of asking one broad question (“Do a full analysis of this paper”), work step by step with precise, focused questions. This produces better answers and lets you critically evaluate each response.
Advanced Techniques

A powerful technique is to ask the LLM to adopt the role of a referee and challenge the paper’s findings. There is extensive representation of referee reports in training data, so LLMs are reasonably good at identifying potential weaknesses. Even if the critiques are not all convincing, reading them helps you think through the paper’s limitations — and if you find the criticisms weak, it may actually reinforce your confidence in the findings.
NotebookLM is especially useful when working with multiple related papers. For example, when studying a new causal inference method like double/debiased machine learning, you often need to understand five other complex foundational papers. Having them all in one notebook lets you ask cross-cutting questions: “What is the identifying assumption for the doubly robust diff-in-diff? How does it differ from the standard approach?” This kind of rapid cross-referencing across technical papers is where the tool really shines.
Best Practices

A few best practices for AI-assisted reading:
- Filter in: Be mindful about the quality of the paper you upload. The quality screening discussed earlier still applies.
- Filter out: Double-check that citations are real and that the model has correctly interpreted results. Do not just trust the output — verify it.
- Work step by step: Ask one precise question at a time rather than requesting a comprehensive analysis. You already get long, detailed answers from a single focused question.
For notebook organization, consider whether your task is recurring or one-off. For a recurring theme — like evaluating causal claims across many papers — a single notebook with many sources works well, because the model can draw connections between papers. For a specific, self-contained question, start a fresh notebook to avoid context from unrelated sources influencing the answers.
Part 3: Practice and Discussion
The best way to internalize these methods is to apply them. In this exercise, the class put both traditional reading and AI-assisted reading to the test on a real paper.
Practice

For the hands-on exercise, students downloaded and analyzed the paper “Who Is AI Replacing? The Impact of Generative AI on Online Freelancing Platforms” by Demirci, Hannane, and Zhu, using NotebookLM alongside their own reading. The instructor discussed this paper in a podcast episode with Xinrong Zhu, one of the authors.
The exercise also included experimenting with NotebookLM’s additional features — infographics, slide decks, flash cards, and mind maps. A first attempt at the infographic and slide deck features produced mixed results: the tool tended to over-emphasize visual elements at the expense of clarity, and the generated slides were exported as images (not editable text), limiting their practical usefulness. As with any tool, the quality improves with practice and better prompting.
Class Discussion: “Who Is AI Replacing?”
The class debrief surfaced several important points about the paper’s methodology and limitations:
Using Google Trends as a proxy for AI awareness. The authors used Google Trends data to show that as public awareness of AI grew, demand for certain freelance jobs dropped more sharply. This adds a useful dimension beyond simply measuring a before/after effect — it captures the mechanism of awareness-driven adoption.
Missing the job creation side. The paper focuses exclusively on job losses in three freelance categories. It does not examine whether new jobs were created as a result of GenAI — for example, roles in AI tool design or prompt engineering. In economics, this is the concept of creative destruction: roughly 10% of jobs in OECD countries disappear every year, and about 10% of entirely new jobs emerge. The critical question is not just the net aggregate effect but the heterogeneity — the people losing jobs are often not the same people gaining new ones (e.g., administrative roles disappear while engineering roles appear).
Difference-in-differences methodology. The paper uses a diff-in-diff design, splitting freelance jobs into high-exposure and low-exposure groups based on an AI exposure classification (following the Eloundou et al. “GPTs are GPTs” framework). The control group consists of more manual-intensive freelance jobs. As the instructor noted, the paper uses robust diff-in-diff estimators, reflecting recent methodological advances since 2020–2021 that showed problems with standard two-way fixed effects.
SUTVA and spillover concerns. A sharp observation from the class: if AI reduces demand for high-exposure freelance jobs, displaced workers might migrate to lower-exposure job categories, artificially inflating demand in the control group. This relates to the Stable Unit Treatment Value Assumption (SUTVA) — the assumption that treatment of one group does not affect the other. The instructor found this an interesting point worth thinking through further: the control group would not be stable but rather positively affected by displaced workers, which could amplify the measured treatment effect. However, the overall effect captured is still meaningful — it is just that the magnitude might be somewhat inflated.
The COVID overhiring confound. One of the most important threats to identification — and one that NotebookLM did not flag — is that the jobs most exposed to AI are also the jobs that were arguably overhired during COVID (remote-friendly, computer-based tasks). The post-ChatGPT decline in these jobs might partly reflect a market correction from COVID-era overhiring, not purely an AI effect. However, a COVID correction would be a slow-moving trend, not a sudden shock coinciding precisely with ChatGPT’s launch in November 2022. The likely reality: the AI effect is real, but it may be somewhat amplified by this underlying confound.
When to Use AI — and When Not To
The practice session demonstrated both the power and the limits of AI-assisted reading. This final section distills those lessons into a practical framework.
The Outcome vs. the Process

If you only care about the outcome — answering a precise question — then AI is great. But if you care about the process — the unexpected connections, the writing instincts you develop, the things you discover that you were not looking for — then starting without AI is valuable. Reading trains your ability to write, to structure arguments, and to communicate precisely. These benefits cannot be automated.
Finding the Balance

The bottom line: use AI when you need efficient extraction of specific information. But do not use it as a substitute for deeply owning a research paper. Read it yourself first, form your own view, and then use AI to challenge or complement your understanding. Balancing AI-assisted and unassisted reading helps prevent skill atrophy — the gradual loss of the very abilities that make you a good researcher.
Homework

For next time: pick a paper related to your master thesis or a topic you are interested in. First, read it fully on your own — dedicate at least one to two hours to really owning it. Then interact with NotebookLM, and compare your understanding with what the tool highlights. You should be able to judge the AI’s output because you already know the paper.
What’s Next?

Next week: Literature Review — how to find, filter, and organize the papers you need to read.
- Read in passes, not cover-to-cover. Use quality screening (journal, citations, year) to filter, then a three-pass approach — quick overview, deeper dive, full analysis — to invest your time where it matters most.
- AI augments reading but does not replace it. Tools like NotebookLM can extract answers, cross-reference papers, and simulate referee reports — but the deep understanding, writing instincts, and critical thinking come from reading the paper yourself.
- If you have not read it, you cannot judge the AI’s summary of it. Always form your own view first, then use AI to challenge or complement your understanding. This is how you prevent skill atrophy and catch hallucinations.